
go语言数据结构
slice
1 | list := make([]int,0) |
编译期:
1 | // cmd/compile/internal/types.NewSlice |
底层数据结构
1 | // reflect.SliceHeader |
Data 是一片连续的内存空间,这片内存空间可以用于存储切片中的全部元素,数组中的元素只是逻辑上的概念,底层存储其实都是连续的,所以我们可以将切片理解成一片连续的内存空间加上长度与容量的标识。
扩容策略
- 如果切片的容量小于 1024 个元素,于是扩容的时候就翻倍增加容量。
- 一旦元素个数超过 1024 个元素,那么增长因子就变成 1.25 ,即每次增加原来容量的四分之一。
总结:
- 谨慎使用多个切片操作同一个数组,以防读写冲突。数组创建切片,实际是data指针指向数组的某个位置。(可以用copy来分隔)
- 通过函数传递切片时,不会拷贝整个切片,因为切片本身只是个结构体而矣
- 使用 append() 向切片追加元素时有可能触发扩容,扩容后将会生成新的切片
map
1 | m := make(map[int]string, 0) |
该操作会执行如下逻辑
1 | func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap { |
hmap结构如下:
1 | // A header for a Go map. |
hamp整体架构图如下

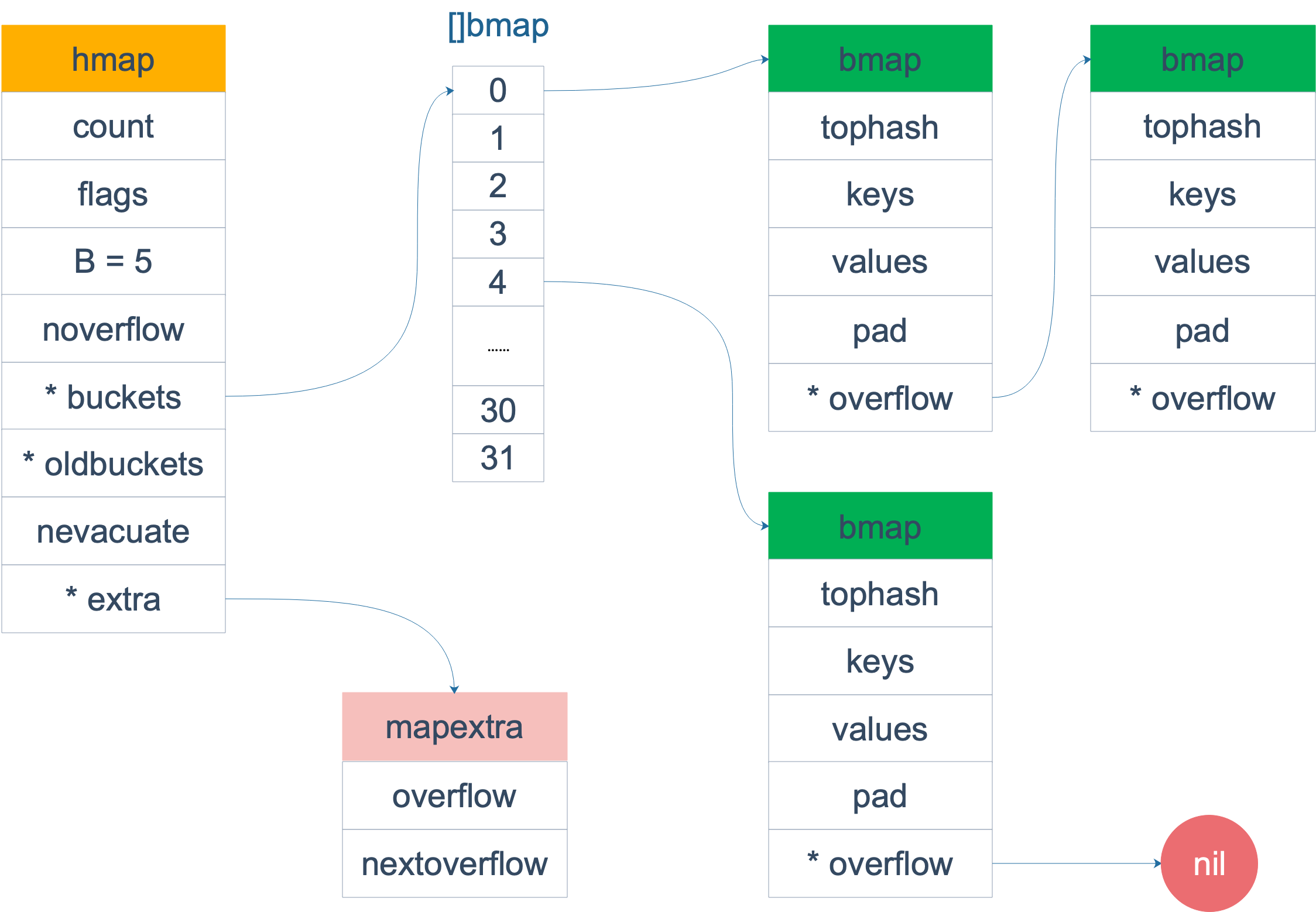
其中:
- B表示存储桶(buckets)的数量:2^B,图中B为5,则表示有32个存储桶
- map插入数据时,先通过low8(hash(key))%B来确定插入哪个存储桶里面,即按照key的hash值低8位来确定放哪个桶
- 存储桶是bmap结构,每个存储桶最多保存8个元素,tophash是key的hash高8位,key和value则分开存储。
- 当某个桶存满了,可以通过overflow继续往后拉链新的hamp
map插入操作
- 函数首先会检查 map 的标志位 flags。如果 flags 的写标志位此时被置 1 了,说明有其他协程在执行“写”操作,进而导致程序 panic。这也说明了 map 对协程是不安全的
- 扩容是渐进式的,如果 map 处在扩容的过程中,那么当 key 定位到了某个 bucket 后,需要确保这个 bucket 对应的老 bucket 完成了迁移过程。即老 bucket 里的 key 都要迁移到新的 bucket 中来(分裂到 2 个新 bucket),才能在新的 bucket 中进行插入或者更新的操作。
- 根据hash高8位确定桶id,低8位确定bmap位置,以及是否要创建溢出桶
- 在正式安置 key 之前,还要检查 map 的状态,看它是否需要进行扩容。如果满足扩容的条件,就主动触发一次扩容操作。
- 更新 map 相关的值,如果是插入新 key,map 的元素数量字段 count 值会加 1;在函数之初设置的 hashWriting 写标志出会清零
map扩容操作
1 | 装载因子 = map中元素的个数 / map的容量 |
- 当装载因子超过6.5时,扩容一倍,属于增量扩容
- 当使用的溢出桶过多时间,重新分配一样大的内存空间,属于等量扩容,实际上没有扩容,主要是为了回收空闲的溢出桶以及降低hash冲突。overflow 的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15
- 扩容采用渐进式扩容。每次最多只会搬迁 2 个 bucket。真正搬迁 buckets 的动作在 growWork() 函数中,而调用 growWork() 函数的动作是在 mapassign 和 mapdelete 函数中。也就是插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。先检查 oldbuckets 是否搬迁完毕,具体来说就是检查 oldbuckets 是否为 nil
·
map查询操作
- hash(key)低8为找到桶id
- 在这个桶里面的bmap用hash高8位对比,每找到从bmap的overflow的下一个bmap找,知道匹配或者不存在
chan
1 | type hchan struct { |
runtime.hchan 结构体中的五个字段 qcount、dataqsiz、buf、sendx、recv 构建底层的循环队列:
- qcount — Channel 中的元素个数;
- dataqsiz — Channel 中的循环队列的长度;
- buf — Channel 的缓冲区数据指针;
- sendx — Channel 的发送操作处理到的位置;
- recvx — Channel 的接收操作处理到的位置;
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 爱开源GoGo!
