
RAG应用
RAG应用
一、RAG简介
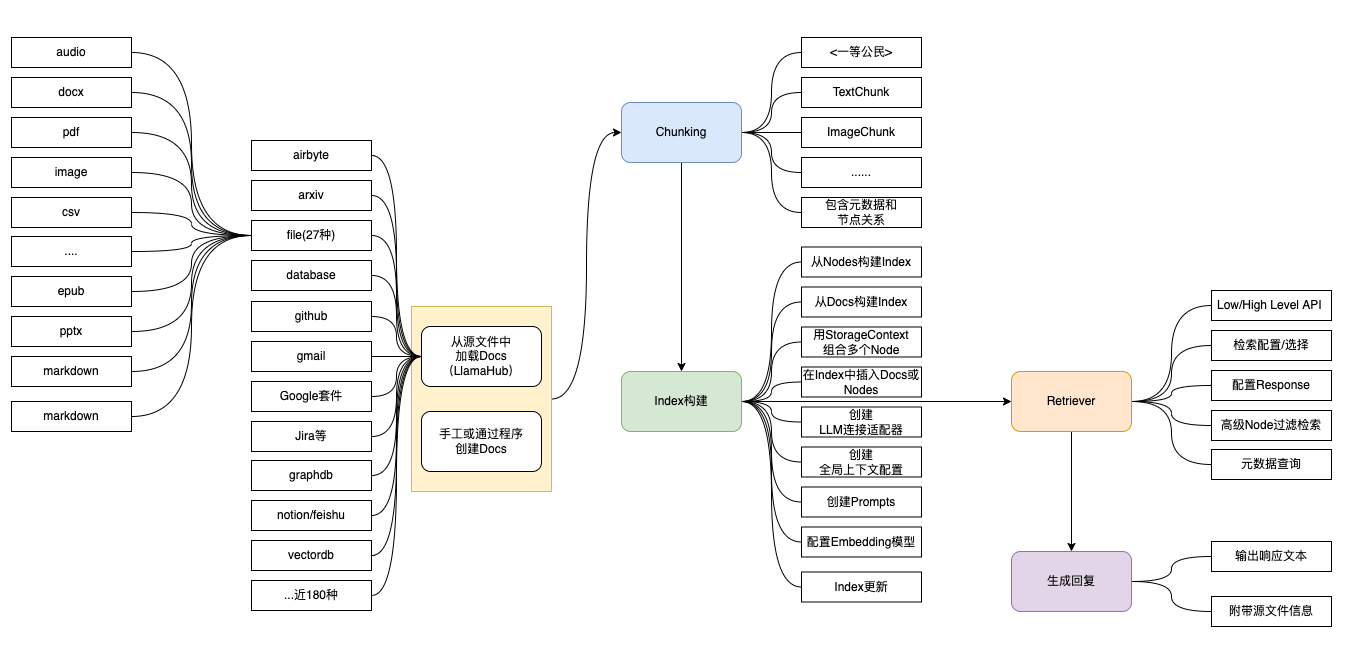
目前实现 RAG 的主流框架就是 LangChain 和 LlamaIndex,LangChain 更适合需要复杂对话流程、上下文管理、以及多步骤任务的应用场景,如聊天机器人、任务自动化等。LlamaIndex 当应用场景主要涉及大量数据的快速检索和查询时,LlamaIndex更加适用,如企业知识问答系统、文档搜索引擎等。
二、llamaIndex构建RAG服务
LlamaIndex最初被称为GPT Index, 后来大语言模型的快速发展,改名为LlamaIndex。它就像一个多功能的工具,可以在处理数据和大型语言模型的各个阶段提供帮助
首先,它有助于“摄取”数据,这意味着将数据从原始来源获取到系统中。其次,它有助于“结构化”数据,这意味着以语言模型易于理解的方式组织数据。第三,它有助于“检索”,这意味着在需要时查找和获取正确的数据。最后,它简化了“集成”,使您更容易将数据与各种应用程序框架融合在一起。

首先安装llamaIndex
1 | pip install llama-index llama_index.llms.ollama llama_index.embeddings.huggingface -i https://pypi.tuna.tsinghua.edu.cn/simple |
可以通过环境变量LLAMA_INDEX_CACHE_DIR控制llamaIndex的cache存储位置,包括huggingface,nltk等包的位置
llamaIndex快速构建RAG
llamaIndex可以快速构建起一个文档索引问答的demo,全部采用默认配置,只需要5行代码
1 | from llama_index.core import VectorStoreIndex, SimpleDirectoryReader |
一般使用时,我们还需要修改llm,embed模型,以及修改prompt来生成中文输出
1 | from llama_index.core import Settings |
文本分析
文档分析即是chunking过程。 LLamaIndex将输入文档分解为节点的较小块。这个分块是由NodeParser完成的。默认情况下,使用SimpleNodeParser,它将文档分块成句子。
分块过程如下:
- 用户pdf,md等文档首先被分割为Document结构,(默认按最大字数或者页码来决定分多少个Document)
- NodeParser接收一个Document对象列表;
- 使用spaCy的句子分割将每个文档的文本分割成句子;
- 每个句子都包装在一个TextNode对象中,该对象表示一个节点;
- TextNode包含句子文本,以及元数据,如文档ID、文档中的位置等;
- 返回TextNode对象的列表。
在LlamaIndex框架中,Document和Node是核心的数据抽象概念,它们帮助处理和组织各种类型的数据以便于索引、查询和分析。这两个概念提供了一种灵活和高效的方式来处理来自不同数据源的信息。一旦数据被摄取并表示为文档,就可以选择将这些文档进一步处理为节点。节点是更细粒度的数据实体,表示源文档的“块”,可以是文本块、图像或其他类型的数据。它们还携带元数据和与其他节点的关系信息,这有助于构建更加结构化和关系型的索引。
1 | from llama_index.core.node_parser import SentenceSplitter |
在core.node_parser中,有诸多文本分割工具如:SentenceSplitter,MarkdownNodeParser,TextSplitter,NodeParser等。
索引构建
索引可以有多种索引,如DocumentSummaryIndex,VectorStoreIndex。效果上DocumentSummaryIndex更优一些
1 | # 直接通过nodes来构建索引 |
文章摘要索引:DocumentSummaryIndex
通常,大多数用户以以下方式开发基于LLM的QA系统:
- 获取源文档并将其分成文本块。
- 然后将文本块存储在矢量数据库中。
- 在查询期间,通过使用相似度和/或关键字过滤器进行Embedding来检索文本块。
- 执行整合后的响应。
然而,这种方法存在一些影响检索性能的局限性:
- 文本块没有完整的全局上下文,这通常限制了问答过程的有效性。
- 需要仔细调优top-k /相似性分数阈值,因为过小的值可能会导致错过相关上下文,而过大的值可能会增加不相关上下文的成本和延迟。
- Embeddings可能并不总是为一个问题选择最合适的上下文,因为这个过程本质上是分别决定文本和上下文的。
- 为了增强检索结果,一些开发人员添加了关键字过滤器。然而,这种方法有其自身的挑战,例如通过手工或使用NLP关键字提取/主题标记模型为每个文档确定适当的关键字,以及从查询中推断正确的关键字。
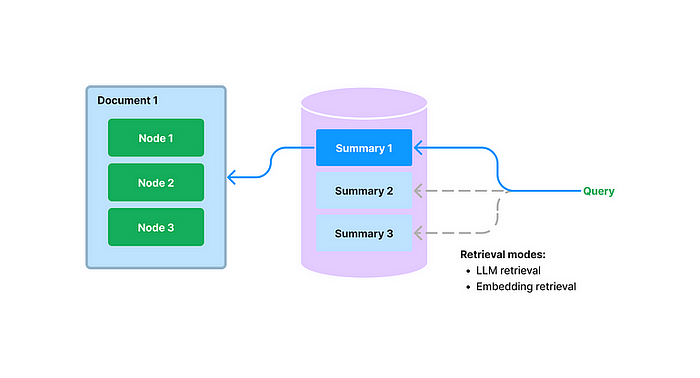

这就是 LlamaIndex 引入文档摘要索引的原因,它可以为每份文档提取非结构化文本摘要并编制索引,从而提高检索性能,超越现有方法。该索引比单一文本块包含更多信息,比关键字标签具有更多语义。它还允许灵活的检索,包括基于 LLM 和嵌入的方法。在构建期间,该索引接收文档并使用 LLM 从每个文档中提取摘要。在查询时,它会根据摘要使用以下方法检索相关文档:
- 基于 LLM 的检索:获取文档摘要集合并请求 LLM 识别相关文档+相关性得分
- 基于嵌入的检索:利用摘要嵌入相似性来检索相关文档,并对检索结果的数量施加顶k限制。
文档摘要索引的检索类为任何选定的文档检索所有节点,而不是在节点级返回相关块。
向量检索
构建索引可以用高级方法如
1 | doc_summary_index = DocumentSummaryIndex(nodes=nodes) |
也可以使用底层api,使用LLM进行索引
1 | from llama_index.core.indices.document_summary import DocumentSummaryIndexLLMRetriever |
使用嵌入向量进行索引
1 | from llama_index.core.indices.document_summary import ( |
混合检索之融合检索(Fusion Retrieval)
一文说清大模型RAG应用中的两种高级检索模式:你还只知道向量检索吗?: https://www.53ai.com/news/qianyanjishu/2024060723184.html
1 | if os.path.exists(temp_dir): |
混合检索之递归检索(Recursive Retrieval)
https://www.53ai.com/news/qianyanjishu/2024060489721.html
使用Llama index构建多代理 RAG https://blog.csdn.net/tMb8Z9Vdm66wH68VX1/article/details/134213080
Llama index概述了使用多代理RAG的具体示例:
- 文档代理——在单个文档中执行QA和摘要。
- 向量索引——为每个文档代理启用语义搜索。
- 摘要索引——允许对每个文档代理进行摘要。
- 高阶(TOP-LEVEL)代理——编排文档代理以使用工具检索回答跨文档的问题。
对于多文档QA,比单代理RAG基线显示出真正的优势。由顶级代理协调的专门文档代理提供基于特定文档的更集中、更相关的响应。
rerank使用
由于考虑召回速度,在执行向量搜索的时候存在一定随机性就会牺牲一点准确性,RAG中第一次召回的结果排序往往不太准确,具体可以参考 Rerank——RAG中百尺竿头更进一步的神器,从原理到解决方案。所以这时候就需要 rerank 一下,来对召回的结果重新排序。这里 LlamaIndex 的给了两个方案,一个是基于大模型的 LLMRerank 类,一个是第三方的 rerank 模型。
- 使用llm的rerank
1 | from llama_index.core.postprocessor import LLMRerank |
- 使用自定义模型
1 | from llama_index.core.postprocessor import SentenceTransformerRerank |
效果,咨询问题为:月工资多少。不加rerank召回为
1 | node_score: Node ID: 08ce241b-8f30-4f5d-b075-3352c09aacdd |
加了rerank,召回为:
1 | node_score: Node ID: 20a75e46-052b-47d0-9051-f434c251835c |
LLMRerank 这个类的原理是,将向量数据库查询的 top 片段,拼装成提示词给大模型,等待大模型按一定的格式返回,然后再将排序之后的片段作为用户提问的上下文,再次拼装成提示词给大模型回答。这里就会有两次请求大模型,就会造成响应明显变慢。所以一般都是采用第三方的 rerank 模型,替换大模型排序这个操作。
召回测评
https://ihey.cc/rag/融合检索-rerank-在-rag-应用中的效果评测/
结论:
- 对最终召回成功率提升最大的是提高 Recall@N 的数量。但这对 LLM 的 Context Length 和 In-Context learning 要求在提高
- Rerank 对检索结果的提升是直接的、确定的(10%~15%),但还是不够理想。对具体某个 query 案例,rerank 小概率会降低召回成功率
- 融合检索比单纯的 Sparse 或 Dense 检索都好,但优势不显著。可能需要针对不同 query 采用不同的融合排序的权重
- RAG 方案最终拼的还是检索能力。对 LLM 来说是 garbage in garbage out。是否是 garbage,取决于检索
langchain构建RAG应用
ragflow构建RAG应用
高级RAG多智能体
智能体(Langchain[35] 和 LlamaIndex[36] 都支持)自从第一个 LLM API 发布以来就已存在。其核心理念是为具备推理能力的 LLM 提供一套工具和一个待完成的任务。这些工具可能包括确定性函数(如代码功能或外部 API)或其他智能体。正是这种 LLM 链接的思想促成了 LangChain 的命名。
智能体本身是一个非常广泛的领域,在 RAG 概述中无法深入探讨,因此我将直接继续讨论基于智能体的多文档检索案例,并简要介绍 OpenAI 助手。OpenAI 助手是在最近的 OpenAI 开发者大会上作为 GPTs 提出的相对较新的概念[37],并在下面描述的 RAG 系统中发挥作用。
OpenAI Assistants[38]集成了许多围绕LLM必需的工具,这些工具我们以前在开源项目中已经见过 —— 包括聊天记录管理、知识库存储、文档上传界面,以及最关键的,功能调用 API[39]。这个 API 的重要功能是能够将自然语言请求转换为外部工具或数据库查询的 API 调用。
在 LlamaIndex 中,OpenAIAgent[40] 类融合了这些高级功能,并与 ChatEngine 和 QueryEngine 类结合,提供了基于知识的、具有上下文感知能力的聊天体验。此外,它还能在一次对话交互中调用多个 OpenAI 功能,从而真正实现智能代理行为。
接下来让我们来了解一下多文档代理方案[41] —— 这是一个相当复杂的设计,涉及到在每个文档上初始化一个代理(OpenAIAgent),这个代理不仅能进行文档摘要处理,还能执行经典的问答流程。还有一个顶级代理,负责将查询任务分配给各个文档代理,并合成最终答案。
每个文档代理配备了两种工具 —— 向量存储索引和摘要索引,它会根据接收到的查询决定使用哪个工具。对于顶级代理来说,所有文档代理都是其工具,可供其调度使用。
这个方案展示了一个高级的 RAG 架构,涉及每个代理做出的复杂路由决策。这种架构的优势在于它可以比较不同文档中描述的不同解决方案或实体,以及它们的摘要,同时也支持经典的单文档摘要处理和问答流程 —— 这实际上覆盖了大多数与文档集合交互的常见用例。
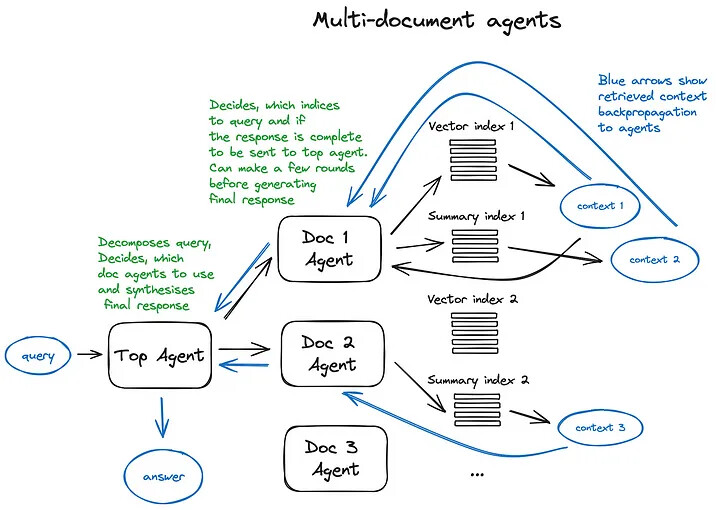

这个复杂方案的一个缺点可以通过图像来理解 —— 由于需要在代理内部与大语言模型(LLM)进行多轮迭代,因此处理速度较慢。需要注意的是,在 RAG 架构中,调用 LLM 总是最耗时的步骤,而搜索则是出于设计考虑而优化了速度。因此,对于涉及大量文档的存储系统,我建议对这一方案进行简化,以提高其扩展性。
该方案可参考:https://discuss.nebula-graph.com.cn/t/topic/14848
参考
- 使用 LlamaIndex 框架搭建 RAG 应用基础实践 https://juejin.cn/post/7341210909068574760
- Rerank——RAG中百尺竿头更进一步的神器,从原理到解决方案 https://luxiangdong.com/2023/11/06/rerank/
- 大模型应用开发,必看的高级 RAG 技术 https://juejin.cn/post/7352146423276568616
- 【RAG实践】Rerank,让RAG更近一步 魔搭+llamaIndex+Qwen+DAG+Rerank https://zhuanlan.zhihu.com/p/691661819
- LlamaIndex官方文档 https://docs.llamaindex.ai/en/stable/
- langchain中文网 https://www.langchain.com.cn/
- 最全的RAG概览 https://discuss.nebula-graph.com.cn/t/topic/14848
